unicode
Unicode is an international standard for character sets used in computers for multilingual text processing but also on the Internet for HypertextMarkup Language( HTML) encoding and also for new Internet protocols. It includes characters and symbols from a wide variety of cultures. The database for Unicode characters is correspondingly extensive, comprising about 230,000 characters and offering a reserve of almost 1 million characters.
The development of Unicode is driven by the Unicode Consortium. The first version is from 1990, and in a certain regularity the Unicode Consortium has presented new and updated versions. In 1991 the version Unicode 1.0, followed by Unicode 1.1, 1996 Unicode 2.0, 2000 Unicode 3.0 and 2003 Unicode 4.0.
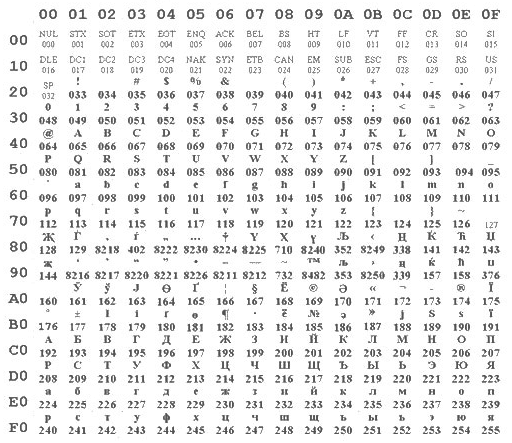
Unicode 3.0 can represent a total of 65,536 characters. This includes Chinese and Japanese character sets as well as Cyrillic, Hebrew, Scandinavian, Arabic, Greek and many more. Unicode knows more than 50 character sets from the most exotic countries. In addition, Unicode knows over 8,000 characters and control symbols. The first 128 characters of Unicode are identical with ASCII according to ISO 8859
In the version Unicode 4.0, which was introduced in 2003, the Unicode experiences an extension by 1,226 new characters compared with the version 3.2. The extensions of the version 4.0 cover symbols for mathematical, commercial and technical applications. For example, characters for currencies. In addition, there are more characters from the Middle East and Southeast Asia, as well as characters from historical scripts and those from Native American scripts.
Unicode 5.0 incorporates all previous changes, including characters needed for some Indian languages, for mathematicians, and for academic use. Internet protocols experience greater stability with version 5.0. Unicode 5.0 provides greater flexibility in segmenting characters, words, and phrases, and higher conformance requirements.
Unicode recognizes various transformation formats, the Unicode Transformation Formats( UTF), with which the Unicode character sets can be transformed for processing. In addition to UTF-8, in which a character is represented by a byte, Single Byte Character Set( SBCS), there are UTF-16 and UTF-32.