pipeline
Pipelines are processor architectures with which the computing power of processors can be increased. The basis of the pipeline concept is the simultaneous execution of several instructions. This means that more computing operations can be performed in the same time as with processors that process all instructions one after the other.
Since with sequentially working processors all single steps from the reading of the instruction over the computation demanded by the instruction up to the result storage in the register take place one after the other, with this processor architecture always only some units are in function, while the others wait for the completion of the operation. The pipeline concept exploits this idle time by having the different functional units execute different instructions simultaneously. For example, on the first clock cycle the 1st instruction can be fetched, on the second the 1st instruction is decoded, at the same time the 2nd instruction is fetched, on the third clock cycle the decoded 1st instruction is read into the register, the 2nd instruction is decoded and the 3rd instruction is fetched, etc.
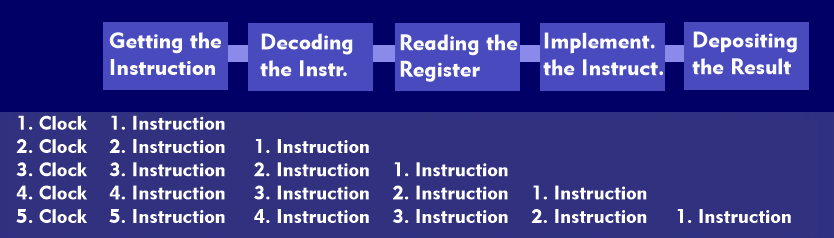
From the implementation point of view, pipelines are divided into individual function sections, the number of which determines the level of the pipeline. If such a subdivision consists of five functions, it is called a 5-stage pipeline.
The cycle time of pipeline processors essentially depends on the stringency of the pipeline, the uniformity of the distribution of the data path logic and its latency.