hash table
The hash table (hashing) is a data structure designed for fast accesses. A mathematical function - the hash function - is used to calculate the position where the elements are stored. The hash function is a mapping of natural numbers to the element range (0 ... table length-1), which maps the so-called key into an address of the table. This calculation is fast and therefore allows a fast access to the element. For this purpose, a hash code is calculated for an element, which depends only on the state of the element and not on other objects, such as predecessors or successors. The disadvantage of hash tables is that the order of the elements is not preserved.
For larger amounts of data stored in the form of arrays or concatenated lists, searching for an element whose position is not known is often time-consuming. The search is performed sequentially element by element until the element in question is found. To solve this problem, the two data structures hash table and tree structure have been developed.
The hash table as an array of lists
A hash table is an array of concatenated lists, so that the search for an element is ultimately an indexed access to a field. The lists are also referred to as buckets. The number of chained lists depends on the number of elements to be stored. In each case, the elements with the same hash code are included in a chained list. The exact position of an element is calculated from its hash code modulo the total number of chained lists.
A hash table is influenced by two characteristics, the capacity and the load factor. However, the capacity should be chosen larger than the expected number of elements by a factor of 1.5 to 2. Otherwise, the probability is too high that several elements are stored in a chained list and thus the efficiency decreases.
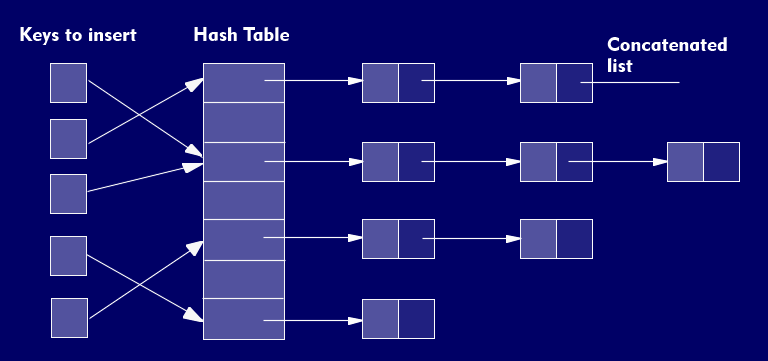
When mapping the key term to the addresses of the array, so-called collisions can occur; i.e. two or more elements are to be mapped to the same index. For this purpose, various collision strategies such as direct concatenation or hashing with open addressing have been developed. Special care must be taken when deleting elements, since occupied table positions must not be released without additional precautions.
If a hash table is completely filled, it is restored to a new hash table with twice as many buckets. The load factor specifies at which fill level this restoring should be performed. The default value for this is 75% in the implemented Java classes, for example.
The quality of the hash table
The quality of the implementation of a hash table is generally dependent on the choice of the hash function. A good hash function should cover all values of the element range with equal probability, in order to also make the collision probability for all table addresses equally probable.
The possibility of the fast search of elements is to be regarded certainly as advantage of Hashing. A disadvantage compared to dynamic methods is the assignment of a static table length. This requires a good estimation of the number of elements to be ordered in advance, in order to avoid disadvantages such as poor memory utilization or poor performance.
To increase the performance of a hash table, there are the following possibilities: Increasing the table size, handling collisions by a better method - e.g. the direct concatenation method and applying a hash function of higher quality.