Die Textkompression ist eine verlustfreie Kompression mit einer Datenreduktion zwischen 20 % und 50 %. Zum Ansatz kommen zwei unterschiedliche Verfahren. Das eine basiert auf der Statistik von Buchstaben und Zeichen, das andere ist das Wörterbuchverfahren.
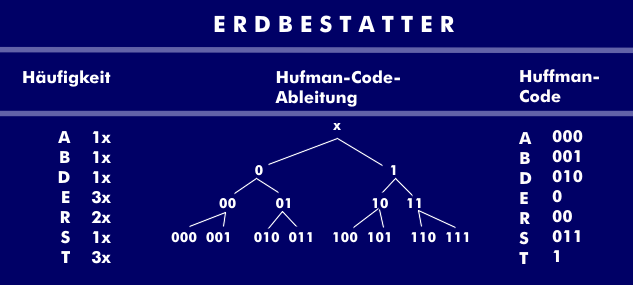
Da Texte Redundanzen in Buchstaben oder Wörtern enthalten, ist das Ziel der Textkompression die Verminderung von Redundanzen. Dies kann sich auf Buchstaben, Ziffern, Zeichen und Binärdaten beziehen wie bei der Lauflängencodierung. Andererseits kann die Codierung auch mit variablen Längen erfolgen. Dabei werden den am häufigsten vorkommenden Buchstaben kurze Bitsequenzen zugeordnet, wie beim alten Morse-Code, bei dem der Buchstaben "e" nur durch das kurze Zeichen (Punkt) der Buchstabe "q" hingegen durch Strich-Strich-Punk-Strich signalisiert wurde. Übertragen auf die Textkompression wird beispielsweise in der Huffman-Codierung die Häufigkeit der in einem Wort vorkommenden Buchstaben erfasst und daraus wird die Substitution abgeleitet.