Die Huffman-Codierung ist eine verlustfreie Quellencodierung für die Text- und Bildkompression. Das Verfahren basiert auf der Redundanz, der Zeichenhäufigkeit und der statistischen Verteilung der Daten einer Information. So treten beispielsweise in einem Text bestimmte Buchstaben häufiger auf als andere, so der Buchstabe "e", der häufiger vorkommt als andere. In einer Grafik sind hingegen die Farben statistisch verteilt: Grün kann beispielsweise häufiger vorkommen als Gelb.
Bei der Huffman-Codierung, die nach dessen Erfinder David Huffman (1925-1999) benannt ist, ersetzt man den am häufigsten vorkommenden Datensatz durch einen kurzen Signalcode, seltener vorkommende Datensätze werden hingegen durch längere Signalcodes ersetzt. Die am häufigsten auftretenden Zeichen werden mit nur 3 Bit (Short Hand) übertragen, das bedeutet, dass man bei einem Zeichen 5 Bit einspart. Manche, selten auftretende Zeichen werden sogar mit mehr als acht Bit übertragen.
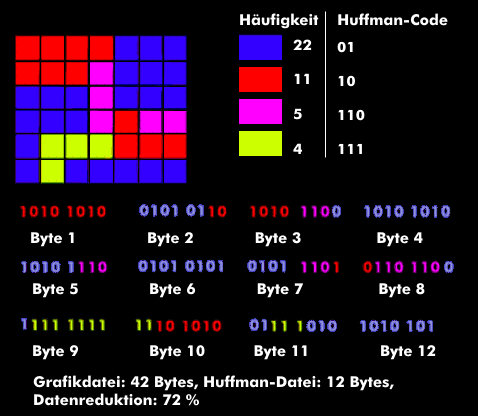
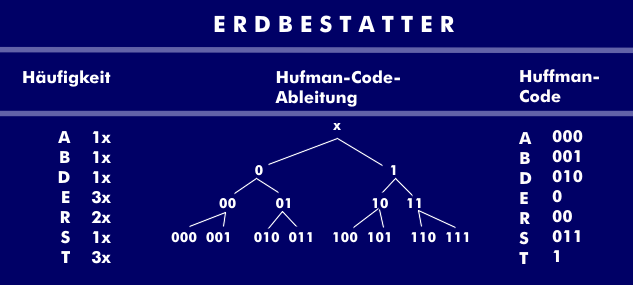
Die Länge des Codes ist also variabel und wird in der Huffman-Codierung anhand der Häufigkeit festgelegt. Dabei wird die Häufigkeit der einzelnen Buchstaben oder Farbpixel ermittelt. Buchstaben/Farbpixel mit geringerer Häufigkeit werden in Gruppen zusammengefasst und aus denen werden in einer Baumstruktur wiederum neue Gruppen gebildet. Je nach Zusammensetzung der Signale können so bis zu 50 Prozent und mehr der Übertragungszeit eingespart werden.
Die Huffman-Codierung wird im H.320 und anderen Videocodecs, in der Gruppe-3 Fax, im Microcom Networking Protocol (MNP5) und in JPEG verwendet.