Der Unicode ist ein internationaler Standard für Zeichensätze, der in Computern für vielsprachige Textverarbeitung aber auch im Internet für die Codierung der Hypertext Markup Language ( HTML) und auch für neue Internet-Protokolle verwendet wird. Er umfasst Schriftzeichen und Symbole aus den unterschiedlichsten Kulturen. Entsprechend umfangreich ist die Datenbank für Unicode- Zeichen, die etwa 230.000 Zeichen umfasst und eine Reserve von nahezu 1 Million Zeichen bietet.
Die Entwicklung des Unicodes wird durch das Unicode-Konsortium vorangetrieben. Die erste Version ist aus dem Jahr 1990. In einer gewissen Regelmäßigkeit hat das Unicode-Konsortium neue und aktualisierte Versionen vorgestellt. 1991 die Version Unicode 1.0, gefolgt von Unicode 1.1, 1996 Unicode 2.0, 2000 Unicode 3.0 und 2003 Unicode 4.0.
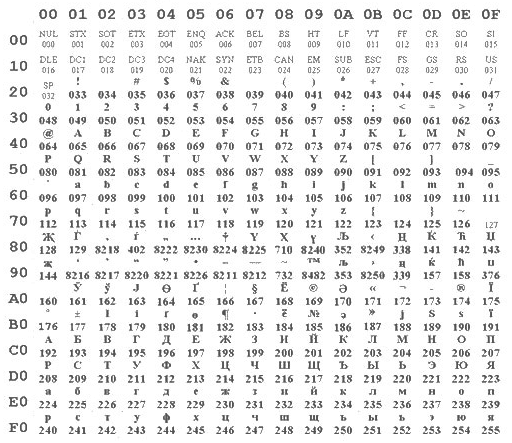
Unicode 3.0 kann insgesamt 65.536 Zeichen darstellen. Darunter fallen chinesische und japanische Schriftsätze ebenso wie kyrillische, hebräische, skandinavische, arabische, griechische u.v.a. Insgesamt kennt Unicode über 50 Schriftsätze aus den exotischsten Ländern. Darüber hinaus kennt der Unicode über 8.000 Zeichen und Kontrollsymbole. Die ersten 128 Zeichen von Unicode sind mit ASCII nach ISO 8859 identisch
In der Version Unicode 4.0, die 2003 vorgestellt wurde, erfährt der Unicode eine Erweiterung um 1.226 neue Zeichen gegenüber der Version 3.2. Die Erweiterungen der Version 4.0 umfassen Symbole für mathematische, kaufmännische und technische Anwendungen. So beispielsweise Zeichen für Währungen. Darüber hinaus gibt es weitere Schriftzeichen aus dem mittleren Orient und Südostasien, sowie Schriftzeichen von historischen Schriften und solchen von Indianerschriften.
Unicode 5.0 beinhaltet alle vorherigen Änderungen einschließlich der Zeichen, die für einige indische Sprachen, für Mathematiker und für den akademischen Gebrauch benötigt werden. Durch die Version 5.0 erfahren Internet-Protokolle eine höhere Stabilität. Unicode 5.0 bietet eine höhere Flexibilität bei der Segmentierung von Zeichen, Wörtern und Sätzen und höhere Konformitätsanforderungen.
Unicode kennt verschiedene Transformationsformate, die Unicode Transformation Formats ( UTF), mit denen die Unicode-Zeichensätze für die Verarbeitung transformiert werden können. Neben UTF-8, bei dem ein Zeichen durch ein Byte, Single Byte Character Set ( SBCS), dargestellt wird, gibt es UTF-16 und UTF-32.